Alpha Zéro
de la société DeepMind-Google
révolutionne la programmation du jeu d'échecs
Certains programmeurs restaient assez septique sur la réussite de
l'adaptation de la méthode de
l'apprentissage profond ( deep
learning ), aussi appelé algorithme d'apprentissage de renforcement
général,
au jeu d'échecs comme pour Alphago au jeu de go.
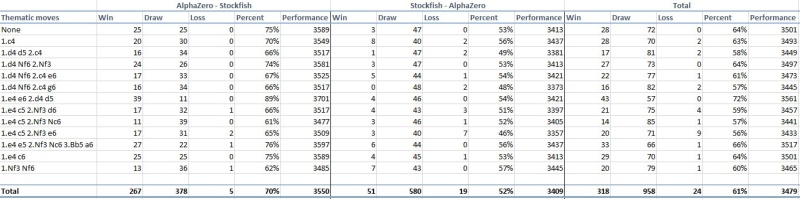
Apparemment, la réussite est pourtant totale en observant les résultats
obtenus
face à l'un des meilleurs programmes de jeu nommé Stockfish.
En effet,
selon DeepMind, après 9 heures d'entraînement face à lui-même et 44
millions de parties
Alpha Zéro, avec son algorithme d'apprentissage de renforcement
général,
a assimilé le jeu d'échecs. Il a ensuite rencontré le
programme Stockfish version 2016
dans un match de 1.300 parties avec un temps de réflexion d'une minute
par coup.
Le résultat laisse incrédule beaucoup de connaisseurs...et semble
presque irréel.